

Common Types of Relationships
Previously, we discussed one-to-many relational databases. By far, this is the most common type of data relationship that we encounter. We discussed parents and children. A parent record can have many child records, but a child record belongs to one and only one parent record. Those relationships are defined through data. A parent record has a primary key that is assigned when a record is created. A child record displays part of the DNA of its parent by carrying the unique parent ID in a foreign key field. When the child’s foreign key value matches the parent’s primary key value we have a link between those records.
Other types of relationships occur as well. In this article, we’ll cover one-to-one and many-to-many database relationships.
Choosing the Right Relationship Type
Those new to database design often have a preconceived notion of what type of relationship fits a pair of entities. It’s easy to jump to a conclusion based on one’s perception of how a business operates. As experienced, gnarly developers, we can say for sure your initial instincts are often wrong.
Database relationships reflect the operations of the underlying organization. In many ways, the Entity Relationship Diagram (ERD) describes the operations in table and field terms. Much like a home builder uses engineering drawings to plan a home that fits the needs of the homeowner, an ERD describes the architecture of a business plan and operations.
Imagine, if you will, there are two entities in your system. These entities are Sales Reps and Customers. Many new designers might quickly jump to the conclusion that a Sales Rep can have many Customers, but a Customer belongs to one and only one Sales Rep, as shown below:
 In many use cases, this is the proper relationship between Sales Reps and Customers. However, it certainly does not apply in all scenarios.
In many use cases, this is the proper relationship between Sales Reps and Customers. However, it certainly does not apply in all scenarios.
Imagine a company like Boeing that sells airplanes. Their customers are large airlines and the military — companies like American Airlines, Southwest Airlines, the US Army and JetBlue.
Customers of this size certainly need more than one Sales Rep each. In fact, they likely have teams of Sales Reps working on multi-billion dollar sales of aircraft. Yet any individual Sales Rep would be assigned to one and only one Customer, as shown below:
 Finally, imagine a scenario where there is a team approach to sales. Customers can buy from multiple Sales Reps on a sales team, and a Sales Rep can sell to many different Customers. This is an example of a many-to-many relationship. Later in this article, we’ll discuss properly resolving a many-to-many relationship in an ERD and Honeycode. For now, however, realize that the following ERD pattern is proper and quite common as well.
Finally, imagine a scenario where there is a team approach to sales. Customers can buy from multiple Sales Reps on a sales team, and a Sales Rep can sell to many different Customers. This is an example of a many-to-many relationship. Later in this article, we’ll discuss properly resolving a many-to-many relationship in an ERD and Honeycode. For now, however, realize that the following ERD pattern is proper and quite common as well.
We hope it’s easy to see that the relationship between any pair of entities does not have a default answer. We, as designers, need to recognize that relationships are based on the context of the organization. Our job as designers and developers is to extract this critical information in discussions with users and manage the system we’re planning.
One-to-One Relationships
Although somewhat uncommon in database systems of the size and complexity created in Honeycode, we do see one-to-one relationships in a handful of situations in database system development.
In essence, we’re saying a single record in table “A” is related to one and only one record in table “B.” And a single record in table “B” is related to one and only one record in table “A.” It’s also possible that a record in “A” or “B” is unrelated to a record in the other. More on this later.
You may ask yourself why these tables are not combined? That’s a great question, actually, and there are multiple use cases where this makes sense.
Many years ago, we dealt with a client with a very large employee table. There were thousands of employees in this organization. A few dozen among the thousands needed very specialized data in addition to the general employee data.
As it turns out, the information was related to security clearances and quite sensitive. Out of an abundance of caution, the company insisted that this information be stored in a separate database with very different security settings. A record in the “Security Info” table would be linked to one and only one record in the Employees table. A handful of records in the Employees table would be linked to one and only one record in the “Security Info” table. Most records in the “Employees” table would not be linked to a record in the “Security Info” table at all as those folks were not involved in classified work.
Data Normalization
Beyond security implications, there’s another reason why data scientists would be inclined to parse out the security information into a separate table.
We’re going to get a bit “geeky” here, so hold on to your keyboards and mice. In more advanced database design, there are data normalization rules and requirements. These are related to set theory in math and are used to provide penultimate data efficiency. They can become quite complex, actually, and a few really achieve advanced levels of normalization.
Large companies with massive data storage systems long ago realized they could save money on data storage by implementing an efficient data design. Imagine a large company like Amazon and how much data is stored for past and present orders as well as products listed for sale.
Some years ago, we were working with a large bank on a department-level solution. We attended a meeting in an enormous conference room that had a long wall covered in a massive ERD during that engagement. It turned out this ERD was used just for their credit card operations. The diagram had hundreds of entities and a very complex set of defined relationships. Of course, this bank employed Ph.D.'s in math and data science, and it was their job to squeeze out efficiency and minimize redundancy. In this diagram were many one-to-one relationships.
The good news is that we, as Amazon Honeycode developers, likely won’t face anywhere near that level of complexity. Our decisions will be based on business needs and logic rather than complex mathematics.
Example of a One-to-One Relationship
Recently we worked with a high-end sports club. They were looking for a system to track many aspects of their business, including members, membership fees, facilities, programs, and much more.
At this facility, they provided members with lockers. At first, it seemed as easy as assigning a locker number to each member. Simple enough, right?
But as we investigated more, we discovered that there was additional information collected on each locker. These included the locker number, size, location, and combination of the lock installed.
Imagine for a moment that this information was stored as part of the Members table. We’d just add a handful of fields to the Members table for that purpose.
Here’s the challenge with that type of combined data structure. If the facility added a number of new lockers that were not yet assigned to a member, where would that data be stored? Would users create new, blank member records to be able to store the locker details? In addition, if a member left the club and the member was deleted from the “Members” table, that would also delete the locker information.
In database terminology, these issues are known as an insertion anomaly and deletion anomaly. Many folks new to data structures fall prey to these issues. It’s the reason we want to track one and only one kind of data in a table. We want to avoid compound record structures where multiple different people, places, objects, or events are stored in the same table.
In this case, we’d create two separate tables for Members and Lockers. Since a member is provided one and only one locker, and a locker is assigned to only one member, we have a one-to-one relationship.
Why Use a One-to-One Relationship
We’ve given two examples of one-to-one relationships. In one case, it was to minimize data storage and provide separate security measures. In the other, we wanted to create a data model that allowed for the creation of data that was truly separate and unique.
We want to advise, however, that it’s easy to overuse these relationships. Be sure not to implement them where they are not needed and not to make an overly complex ERD where one is not needed.
For example, according to very strict readings of data normalization rules one might feel a one-to-one relationship is needed. But also recall that many of these very stringent rules were created in a day and time when computer storage was extremely expensive. The amount of storage we have on our current mobile phones would have cost tens of millions of dollars 50 years ago.
One of the normalization rules says that an attribute (field) should only belong to a table if there’s a value for each and every instance (record). We know that most people have a home phone number, but there are exceptions. Under strict interpretation, we would place the home phone number in a separate one-to-one file.
We think that’s overkill in this day and age. Lack of a value can convey meaning too. In an odd sense having no value tells us that it does not exist. Or we don’t know the value as yet.
For example, the lack of a home phone number could tell us that this person does not have a home number. That’s becoming more and more common with ubiquitous mobile phones. Or it could tell us that we simply do not have the data yet.
Be prudent in your use of one-to-one relationships. They do have value and are important under some circumstances. Use them wisely and carefully where applicable. But don’t get carried away.
Many-to-Many Relationships
As we mentioned previously, many-to-many relationships are quite common in database design. We often discover them only after discussions with system users and management. In many cases, they are not obvious until use cases are defined, and business needs investigated.
Some many-to-many relationships are obvious. There’s a classic example we use in teaching relationships that involves Students and Classes.
Intuitively we know that a Student generally will take many Classes. And a Class will likely have many Students. Thus a many-to-many, as shown below.
 The question becomes, how do we implement a many-to-many relationship in our Honeycode systems?
The question becomes, how do we implement a many-to-many relationship in our Honeycode systems?
Many developers first attempt putting a foreign key field in both Students and Classes tables to solve this data need. It makes sense to new folks since we used a foreign key to resolve a one-to-many relationship. However, that won’t work for a variety of reasons.
Let’s visualize the problem for a moment. We have a table of Students and a table of Classes, as shown below:
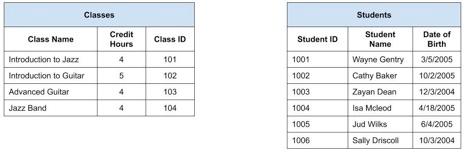
Imagine this information is printed on a large piece of paper and hung on the wall. The school registrar would like to see a diagram that demonstrates which Students are enrolled in which Classes.
I think most would do so by drawing lines between the Classes and Students. By following the lines, either way, we could see who is linked to each Class, or which Classes each Student is enrolled, as follows:
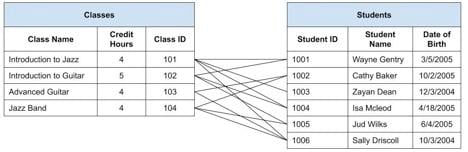 Although a bit messy and hard to follow this series of lines accurately describes the many-to-many relationship between the entities. Each Student can be enrolled in one or more Classes. Each Class can have one or more Students enrolled. Just follow the lines from either side. Each line represents one Student enrolled in one Class. Count up the lines, and you know how many class enrollments exist.
Although a bit messy and hard to follow this series of lines accurately describes the many-to-many relationship between the entities. Each Student can be enrolled in one or more Classes. Each Class can have one or more Students enrolled. Just follow the lines from either side. Each line represents one Student enrolled in one Class. Count up the lines, and you know how many class enrollments exist.
So how do we represent those lines in data? The answer is straightforward. When we have a many-to-many relationship, we add a third join table in the middle to track all these links. In the above case, we’d likely have a table called Enrollments. In essence, we’re converting the lines in the diagram to records and data.
 Notice the many-to-many relationship has been converted into a pair of one-to-many relationships to our new entity Enrollments. Further, notice that Enrollments is the “many” side of both relationships with two crow’s feet attached to it. As discussed in the previous article, the crow’s foot designates the child side of a relationship. Enrollments is a child of both Students and Classes, and thus Enrollments will have two foreign keys, one each for Students and Classes.
Notice the many-to-many relationship has been converted into a pair of one-to-many relationships to our new entity Enrollments. Further, notice that Enrollments is the “many” side of both relationships with two crow’s feet attached to it. As discussed in the previous article, the crow’s foot designates the child side of a relationship. Enrollments is a child of both Students and Classes, and thus Enrollments will have two foreign keys, one each for Students and Classes.
We described that in Enrollments, we’d convert the lines from the diagram above to data. Each line starts at a student record and ends at a class record. Each row in the Students table has a unique Student ID, and Classes have a unique Class ID. Each line thus becomes defined by the starting Student ID and ending Class ID. Each enrollment would carry the ID of its parent records, both Students and Classes, as shown below.
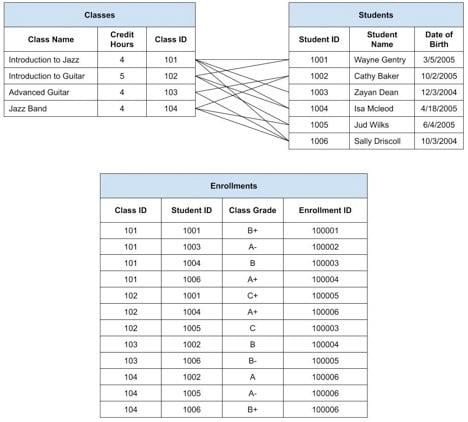 We’ve left the lines between Students and Classes to make it easy to see how each line translates into a row in the table Enrollments. Notice as well that the Enrollments table can have other attributes. We have a Class Grade attribute. If we think about it rationally, a grade is not an attribute of a Student, nor a Class. It’s a characteristic of a Student in a Class and thus belongs on Enrollments. We could imagine other attributes like teacher’s notes, number of absences, or tuition cost for each student.
We’ve left the lines between Students and Classes to make it easy to see how each line translates into a row in the table Enrollments. Notice as well that the Enrollments table can have other attributes. We have a Class Grade attribute. If we think about it rationally, a grade is not an attribute of a Student, nor a Class. It’s a characteristic of a Student in a Class and thus belongs on Enrollments. We could imagine other attributes like teacher’s notes, number of absences, or tuition cost for each student.
In Honeycode, we would create all three tables as shown above. As discussed earlier, Rowlinks in Honeycode are created in the child table to the parent table. In this example, we’d create one Honeycode Rowlink from Enrollments to Students, and another Honeycode Rowlink from Enrollments to Classes.
One other item to notice, each row in the Enrollments table also has a primary key attribute called Enrollment ID. Primary keys are used to link a child record to parent records, and you may wonder if we need a primary key in Enrollments as it has no related child table. Best practice shows that we should have a primary key for rows in all tables. There are other more advanced uses of primary keys that are beyond the scope of this article. There are times when we’ll need to identify the unique ID of a row during automation or integration scenarios.
The great news for us is that Honeycode takes care of generating primary keys automatically and invisibly. It’s there even if you don’t see it. And it’s really beneficial under some key areas of functionality.
When a One-to-Many turns into a Many-to-Many
There are common use case patterns we see that can change the type of relationship used in system design. What follows are some examples.
The key to building a successful ERD and Honeycode system is communication. We can’t help solve an automation need without fully exploring and understanding how a business operates.
In many ways building a custom system is like a tailor making a custom suit. It starts with extensive measurements, choice of jacket and pant style, materials to use, and more. The tailor designs the suit around our body style, much like custom software is built around a business’s needs and operations.
Let’s assume we’re building a relatively simple order entry system where customers can place orders for goods from our website. Each customer can have multiple shipping addresses attached to their account, and they choose one of their shipping addresses for that order during checkout. In this case, we’d have an ERD that contains a one-to-many relationship between the Shipping Addresses entity and the Orders entity. An Order ships to one and only one address, but a Shipping Address may be linked to many different Orders.
 However, in further discussions with the client, it becomes apparent that sometimes customers ship orders to more than one address. For example, a customer may order a number of similar floral arrangements as holiday gifts and have each of them shipped to a different address. In this case, an Order can have more than one Shipping Address, and a Shipping Address can be used on more than one order. So our relationship becomes a many-to-many, as shown below.
However, in further discussions with the client, it becomes apparent that sometimes customers ship orders to more than one address. For example, a customer may order a number of similar floral arrangements as holiday gifts and have each of them shipped to a different address. In this case, an Order can have more than one Shipping Address, and a Shipping Address can be used on more than one order. So our relationship becomes a many-to-many, as shown below.
 First and foremost, this change to a many-to-many is more complicated than we’ve shown here. This change requires a fair amount of reorganization of the ERD. There are rather sweeping ripple effects required for an atypical but important use case.
First and foremost, this change to a many-to-many is more complicated than we’ve shown here. This change requires a fair amount of reorganization of the ERD. There are rather sweeping ripple effects required for an atypical but important use case.
That’s why we want to get an ERD right the first time. Sometimes changes to an ERD are relatively simple. But some require substantial change. If we’ve already built a business system in Honeycode, we’d be making some challenging development changes.
These are often referred to as fringe or edge cases. These are events that don’t happen often but still need to be considered. We only discover the fringe cases through a thorough analysis of a system and repeated conversations with both users and management. Often users are more aware of these fringe cases because they are on the front line dealing with customers and their questions and problems.
As with all relationship decisions, we should examine each change carefully for necessity. It’s possible to turn a one-to-many into a many-to-many when not strictly needed. If there are fringe or edge cases that happen very rarely, we might look for a workaround for those circumstances.
Assume we only had one instance a year of customers requiring multiple shipping addresses. It would be reasonable to require that customer to place separate orders instead, each with a singular shipping address. It’s less than ideal, but in software development, we need to weigh the incremental cost and complexity of a change with the derived benefit.
Wrapping Up
Please remember that creating an ERD is creating a roadmap for the structure of your database system. Later additions or modifications can be easy or very challenging and require lots of effort. It’s best to get it right the first time.
There are a lot of similarities between designing a home and designing a database. Imagine everyone agreeing on a home design plan. The builders create a home that is exactly as specified on the plans. When the client walks in for the first time, they ask for a few small changes.
First, they’d like the color of the bedrooms to be changed. That’s akin to making a change to the user interface of a system and generally relatively easy to accomplish. But then the client realizes that the kitchen does not get the morning sun, so they’d like the kitchen moved from the west side of the home to the east side. Now I think everyone realizes that a massive change requires lots of deconstruction and reconstruction. Oh, for good measure, the client decides to push the foundation out another 4 feet in each direction. At that point, it might be easier to tear down the existing structure and build from scratch. And, yes, that happens in the building of database systems too. Sometimes clients can’t really envision what they’re asking for, but they know it’s not what they want when they see it.
Fortunately, Honeycode is a no-code tool. From personal experience, we can say that significant changes are simpler in no-code environments than in low- and pro- code platforms. Instead of writing code to change the order of objects on a form, we can click and drag them. It’s easy to create new forms to take the place of existing ones. And because Honeycode takes care of a lot of the relational linking for us behind the scenes, our work is lessened when changes are needed.
Regardless of the complexity of your systems or the tools you use to build them, please be sure to take the time to plan before developing anything concrete.
If you would like to learn more about Amazon Honeycode and how to create useful custom business solutions, feel free to contact us.
