

What is a Database?
A database is an organized method of storing information in a computer system. There are many different database products on the market, but they all boil down to keeping track of your important personal or organizational information.
Before databases, every library had a card catalog cabinet that described, in alphabetical order, what books were on the shelves and where they could be found. It looked like this:

Photo by Maksym Kaharlytskyi on Unsplash
Our librarians spent immense amounts of time keeping the cards in the proper order and helping hapless users try to find the reference they need. They were also responsible for discovering and replacing missing cards. The drawers were designed to be removable, so if another user happened to take off with the drawer one needed, it was tough luck.
With the dawn of ubiquitous computing power, these card catalog stores of data are now maintained in computer-based database systems. It’s faster, allows access from almost anywhere, and provides various controls over the underlying data. In a word, this solution is just better.
In a previous article, we discussed some of the best practices for creating a new database system. At the beginning of the process, we’re really sizing up the business problems and planning what’s needed to help the organization. In the middle, we start arranging the data elements into cohesive groups of tables and fields to solve these problems. In the final stages, we go back to the computer and begin building.
How Is Data Linked?
At some point in time, every person building a database will be confronted with how to link data together from different tables. It’s the foundation of database systems development, akin to building the frame of a house that will hold together all the features we want inside.
Long before computers were available, we, as humans, used very similar techniques to organize people and things. The military uses a series of insignias to display rank. Most of us have seen color-coded medical charts in the doctor’s office. Some of us might know that traffic signs have different shapes depending on their meaning. For example, octagonal shapes are used exclusively for Stop signs. Words, numbers, images, shapes, and colors have been used to distinguish and identify people, places, and things.
What follows is a beginner’s view of how data is linked in most database systems today.
Building a New Honeycode Database System
Imagine for a moment that you own a small children’s summer camp. For this analogy, we’ll call it “Camp Honeycode.”
At Camp Honeycode, we have thirty campers and three camp counselors. Each counselor is responsible for several children in their group.
The campers stay anywhere from one week to all summer. Each week the roster of campers changes. Counselors can change as well during the summer. It’s really difficult for anyone to remember which counselor is responsible for which child.
Every morning there’s a line-up of young campers for the owner to greet and discuss the day’s activities. One morning the owner sees a new child who needs some attention or help. Yet, the camp owner can’t recall which counselor is responsible for that child. Below is a diagram that visualizes this situation.

Notice there’s nothing that connects the counselors to their respective campers. The current camp system relies on individual memory.
The camp owner calls together the counselors to develop a plan to solve this problem. They decide that color-coding their clothing is a good way to bring organization to the situation.
Each counselor will wear a hat of a unique color. And all of their campers will wear a t-shirt of the same color. Now, if a child needs help, it’s easy to identify the responsible party.
I remember my own days at camp decades ago. Our cabin was part of the “Eagle” group. The cabins had an animal name and that animal’s picture was displayed outside our cabin’s door. In database terminology, “Eagle” was a foreign key that was used to determine the group to which we belonged.
The diagram below demonstrates how this could work at Camp Honeycode.

You can tell by glancing at this image that color is used to link items. In database systems, data is used to link records.
Amazon Honeycode takes care of linking records for you via rowlinks. Once a rowlink has been created, Honeycode creates all the keys you need. Rowlinks are the way that database developers express their database structure in Honeycode.
Understanding Primary and Foreign Keys
A key field is data that’s used to link records in one table to records in another. In the Camp Honeycode example, if the camp owner sees a child wearing a green t-shirt, they can scan the camp counselors for a green hat to match. The same happens in relational database systems. When a database sees a child record they can scan the table of parent records for a key match.
The most common relationship in the database world is known as a one-to-many relationship. The parent record represents the “one” side. The child record(s) represents the “many” side of the relationship.
In an Entity Relationship Diagram (ERD), you’ll often see the following symbols representing a one-to-many relationship:

The “Camp Counselors” table represents the parent side of this relationship. The “Campers” represent the child, or the many side of the relationship. This diagram depicts that one “Camp Counselor” record links to many different “Campers” records. But each “Campers” record can link to one and only one “Camp Counselors” record. A parent record can have many child records, but a child has one and only one parent record.
Each parent record has a Primary Key. I remember this as Parents have Primary Keys. A Primary Key is a value in a field or column that uniquely identifies the record in that table. In general, a Primary Key does not contain any data that describes the record. It’s only there for linking purposes and has no other meaning. In general, we expect the following from Primary keys:
- Uniquely identifies each record
- Machine assigned
- Never edited or reused
We don’t use descriptive data for keys that link things together because that data could change. If, for example, we used “company name” as a key field, what happens to all the linking if/when the company’s name changes? All links would be broken and we’d end up with a lot of orphaned child records.
Many companies used Social Security Number (SSN) years ago as a unique identifier of workers. However, there have been many examples of the Social Security Administration issuing duplicate numbers in error. Uniqueness is very important and that’s why random, machine-assigned, long strings provide us with the best chance of upholding that standard.
Within Honeycode, these primary key values are generated behind the scenes to make life easier for the developer. The Universally Unique Identifier (UUID) is an industry-standard method to ensure uniqueness, and is assigned to each record in a table.
Notice the crow’s foot on the many side of the relationship in the ERD. The crow’s foot identifies the child table in the relationship. A child table will carry with it the identity of its parent. Better said, in a field known as the foreign key, a child record will store the universally unique identifier (UUID) of its parent. And that’s the link that shows an association. A child’s foreign key value matching a parent’s primary key value is really the same as a Camper’s t-shirt color matching the Camp Counselor’s hat color. Matching characteristics create a bond between the records.
For Honeycode users, the good news is these UUID values and links are created behind the scenes for you after a Rowlink is created. A Rowlink is an association between a parent and child table that is established through matching values. When creating a child record, a user will generally be asked to identify the parent, and then Honeycode takes care of the underlying linking values behind the scenes.
Even though Honeycode is a very gracious host that takes care of the linking for us, it’s important for all developers to understand the underlying concepts. Remember that one creates a Rowlink from a child table to a parent table. In essence, the child carries the identity of its parent, much like a human carries matching DNA of their biological parents.
Moving Towards Data Tables
In the real world example above, we used hats and t-shirts to link records. At the moment, our data tables would look like this:
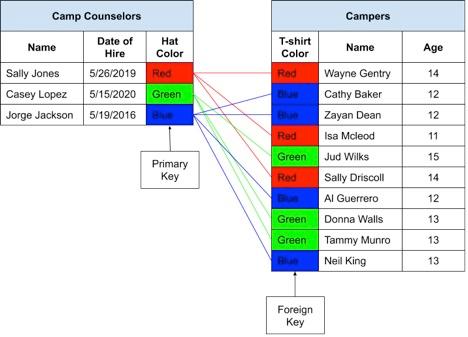
To be clear, there would likely be many other columns in both tables to further describe the underlying entity. This has been abbreviated for demonstration purposes. In fact, the “Campers” table would also have Honeycode generated primary keys as well, but they’re not shown in this diagram for the sake of simplicity.
However, when creating a true, computer-based system, we would not use data to link rows. There are many reasons for this, but the most crucial is that data is designed to change. We don’t want underlying data changes to destroy established links.
In real life today, Primary Keys are generally based on UUID’s, as described above. These are machine-generated, long strings that are virtually guaranteed to be unique. Here’s what a UUID looks like:
b1d12e68-a482-4bc2-833a-fe77da5d1869
Our tables would be linked via these UUID’s that are stored behind the scenes in Honeycode. You can be sure they’re there, but the complexity of managing them is Honeycode’s responsibility, not that of the developers using the product.
In the example below, we’ll show how a real data table might look. In this example, we’ve used short integers as Primary Keys rather than very long UUIDs to simplify the illustration.
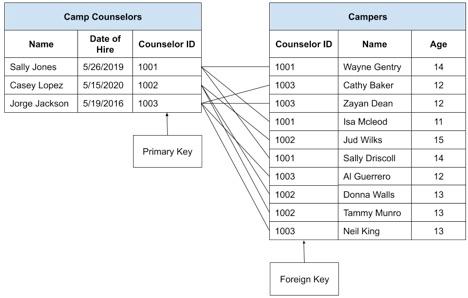 This becomes quite important when designing your systems. It’s important to know what tables link to others and the nature of the relationship. And that helps us build a system that stores data in a manner that’s representative of our organization’s operations.
This becomes quite important when designing your systems. It’s important to know what tables link to others and the nature of the relationship. And that helps us build a system that stores data in a manner that’s representative of our organization’s operations.
The more we know about our tables and their structures, the more value our database system will provide. If you're interested in learning more about building applications using Honeycode, don't hesitate to contact us.
